

Summary
왜 Knowledge distillation은 Soft Label을 사용하는가?
Knowledge distillation (Teacher-Student Learning)
이미 학습 된 큰 모델을 학습 시키고자 하는 작은 모델이 따라하는 방식으로 학습이 가능하다. 학습된 모델로 unlabeled 데이터셋을 pseudo-label을 주고, 이를 바탕으로 학습하는 방법으로 사용한다. 피어세션에서 pseudo-labeling은 언제 사용하는 것이며, 정말 효과적일까 하는 질문이 있었다.(정확히는 soft lable을 활용해서 학습하는 것, pseudo label과는 약간은 다르다.)
멘토님과도 토의를 했었는데, 추가적으로 궁금한 부분이 있어서 논문을 한 번 찾아보았다.
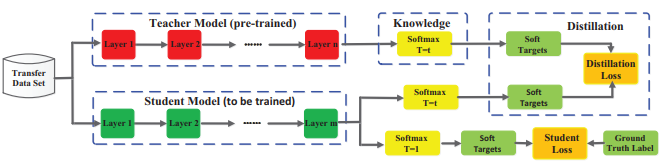
[Jianping Gou 2020. Knowledge Distillation: A Survey, p.6] 출처 : Knowledge Distillation: A Survey
왜 Soft Label을 사용하는가?
먼저, loss를 좀 더 자세하게 살펴보자.
(관련 논문 : Knowledge Distillation and Student-Teacher Learning for Visual intelligence)
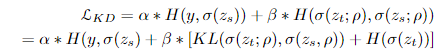
[Knowledge Distillation and Student-Teacher Learning for Visual intelligence, p.3] What is KD and Why Concern it?
전반적인 Loss를 다음과 같이 표현한다.
H는 loss function, y는 ground truth, σ는 softmax funtion, 그리고 z는 각 logit을 의미한다.
그렇다면 logit은 무엇일까? logit은 sigmoid의 역함수라고 생각할 수 있다.
logit을 K개의 class로 일반화 하면 softmax가 유도된다.
즉, class가 2개인 경우 logit으로 softmax를 표현하면 다음 같이 표현된다.
\[exp(t) = {y\over1-y}\]
이를, 논문에 적용하면 다음과 같이 표현된다.

[Knowledge Distillation and Student-Teacher Learning for Visual intelligence, p.2] What is KD and Why Concern it?
다시 Loss를 살펴보자. Distillation Loss와 Student Loss의 합으로 표현되어 있다.
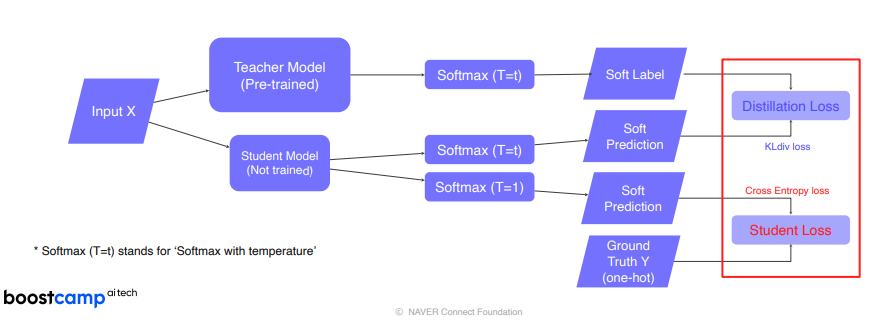
즉, 이전에 bias와 variance와 마찬가지로 Trade-off를 고려해서 total Loss가 최저가 되는 α와 β를 찾아야 한다. 이 부분은 학습하면서 α와 β를 조절하면서 찾게 된다. 하지만 불균형한 클래스에서 이 둘의 최적은 찾기 쉽지 않을 것이다. 이를 찾기 쉽도록 하기 위한 것이 바로 Re-weighting과 soft label이다. Re-weighting으로 label 분포를 부드럽게 만드며, soft label을 통해서 좀 더 유연하게 α와 β 값을 찾도록 도와준다. 이 과정에서 over_fitting, under_fitting 문제도 해결 된다. soft 혹은 hard와 무관하게, distillation loss으로만 학습한다면 학습이 계속 진행되면 당연하게도 distillation loss는 줄어들 것이다. (아마도) 하지만, 그 경우 student loss도 줄 것 인가? Loss는 결국 distillation loss와 student loss의 합으로 생각하기 때문에, 어느 하나만 줄인다고 해결되지 않고, 이 둘의 합이 최저가 되는 부분을 찾아야 한다. 이를 위해서는, ‘어느 비율로 합쳐서 학습하는 가?(α와 β의 최적의 값)’도 중요하지만, 논문에서는 그 값을 찾기는 쉽지 않다고 하는 것 같다. (내가 이해한 것이 맞다면) 그래서 ‘학습을 어떤 방법으로 하는 가’도 중요할 것 같다.
추가적으로 다른 논문에서 다음과 언급이 있다.
(관련 논문 : Does Knowledge Distillation Really Work?)

[Does Knowledge Distillation Really Work?, p.9]
정리하자면, optimization은 너무나도 어렵기 때문에 더 쉬운 방법을 찾았고 그 방법이 soft label이라고 생각한다.
soft label로 학습하게 되면, over_fitting이 방지 되면서, generalization이 향상되고 student loss가 hard label로 학습할 때에 비해서 낮게 나오기 때문에 soft label이 사용된다고 생각한다.
시간이 지나고 다시 보니 이 부분은 틀린 것 같다.
위 언급한 논문 내용은 학습해보지 않은 새로운 데이터로 teacher에 입력하게된다면, 큰 효과를 보지 못한다는 말이다.
추가적으로, 적절한 alpha 값을 찾는 것은 어렵다. 그것은 사실이다.
따라서 최적화에 힘쓰기보단, 적절한 student 모델을 찾는 것이 성능을 올리기에 적합할 것이다.
Student 모델의 성능이 좋다고 knowledge distillation의 결과가 항상 좋은 것이 아니며, 적절한 조합이 필요하다.
Knowledge distillation은 self-distillation으로도 자주 사용되다. 이 경우 성능이 높아진다고는 보장할 수 없지만, 일반화만큼은 상당히 뛰어나다고 한다.
해당 논문에서는 α와 β의 값에 따른 loss를 visualization 하여 비교한다.
값에 따라서 보이는 경향에 대해서도 언급된다.
Discussion 부분을 보면 "어렵게 굳이 최적화의 값을 찾을 필요는 없다. "라는 것 같다.
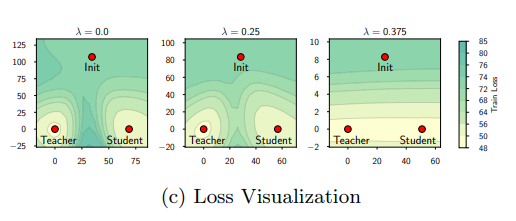
[Does Knowledge Distillation Really Work?, p.10]
그 외에도 KD 학습은 다음의 표의 방법들로 성능을 올린다.
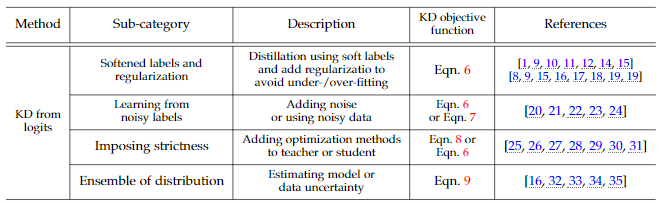
[Knowledge Distillation and Student-Teacher Learning for Visual intelligence, p.6]