
딥러닝은 무엇일까?
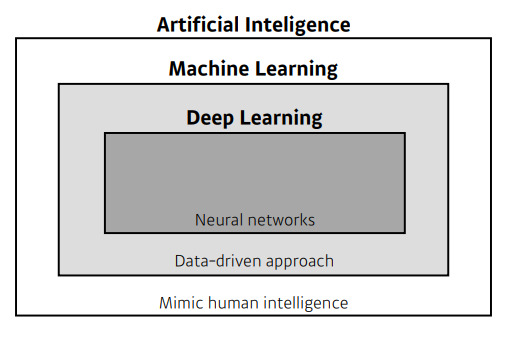
지난 몇 년간 인공지능(Artificial Intelligence)은 일상 속 다양한 부분에서 접할 수 있었고, 이 용어는 더 이상 낯설지 않게 되었다. 그리고 그런 AI와 항상 같이 언급되는 머신러닝(Machine Learning), 딥러닝(Deep Learning)은 무엇을 의미하고 어디에 활용될까?
머신러닝은 인공지능의 하위 분야이며, 딥러닝은 이런 머신러닝의 하위 분야로 여긴다. 이 글에서는 이 용어에 대해서 각각 알아보고 설명하고자 한다.
1. 인공지능
인간의 지능을 모방한 인공지능
인공지능은 인간의 지능을 기계나 컴퓨터를 통해서 모방하고자 만들어진 개념이다. 인간의 인식, 판단, 추론 그리고 그에 대한 말이나 행동, 학습과 같은 인간의 지능을 이해하는 컴퓨터 시스템을 의미한다. 2016년 전 세계의 이목이 집중했었던 알파고를 기억하는가? 구글 딥마인드에서 개발한 바둑 인공지능 프로그램으로, 바둑은 체스와 같은 게임과 다르게 가능한 수가 훨씬 크기 때문에 많은 사람들에게 충격을 주며 인공지능이라는 용어를 대중화시켰다.
정말 지능을 갖고 있다고 볼 수 있을까?
우리가 사용하고 있는 인공지능은 아직 인간의 지능을 완벽하게 모방했다고 하기에는 부족한 부분이 많다. 앞서 말한 알파고 또한 바둑이라는 특정한 문제를 해결하기 위해 개발된 도구에 불가하다. 하지만, 그럼에도 이미 인간의 능력을 뛰어넘은 성능을 보여준다. 이렇듯 앞으로의 발전 가능성이 무궁무진하다는 것이 바로 인공지능의 매력이다.
2. 머신러닝
데이터를 학습하는 머신러닝
머신러닝은 데이터에서 일반적인 규칙을 도출하기 위한 알고리즘을 의미한다. 즉, 머신러닝이란 컴퓨터가 스스로 학습할 수 있도록 알고리즘을 개발하는 것을 의미하며 데이터의 특성이나 원하는 결과에 따라서 크게 지도(Supervised), 비지도(Unsupervised), 준지도(Semi-supervised), 강화(Reinforcement) 학습으로 나뉜다.
- 지도 학습 : 주어진 데이터에 대해 예측하고자 하는 값을 제공하고, 이에 맞춰 회귀(Regression) 혹은 분류(Classification)의 문제로서 결과를 예측하는 것을 의미한다.
- 비지도 학습 : 자율 학습이라고도 불리며 다른 학습방법과 달리, 주어진 데이터에 대해 목표가 주어지지 않는다. 주어진 데이터가 어떻게 구성되어있는지를 알아내는 것을 문제로서 데이터의 주요 특징을 확인한다. 비지도 학습의 대표적인 예로는 클러스터링(Clustering)이 있다.
- 준지도 학습 : 목표 값이 있는 데이터와 없는 데이터를 모두 훈련에 사용하는 것을 말한다. 이러한 학습방법을 사용하는 이유는 데이터를 처리하기 위해서는 어느 정도 훈련된 사람의 손을 거쳐야 하며 그 비용은 매우 크기 때문에 최소한의 비용으로 성능을 향상시키기 위함이다.
- 강화 학습 : 대부분의 학습의 경우 마르코프 결정 과정 문제를 해결하는 방식으로 학습한다. 강화 학습의 경우 특정한 정답이 주어지는 것이 아닌 보상이라는 개념을 통해 보상을 최대한 많이 얻도록 학습을 하여 목표를 찾아가게 된다.
지금까지의 프로그래밍은 데이터에 규칙을 적용해서 해답을 도출했다면, 머신러닝의 경우 데이터와 해답을 주고 이에 대한 규칙을 찾아가는 과정이라고 볼 수 있다.
3. 딥러닝
기존 머신러닝의 한계를 돌파한 딥러닝
딥러닝 이전의 머신러닝의 경우 인간을 통해서 특징을 지정해주는 과정이 필요했다. 그 과정에서 인간의 편향과 시각의 차이로 인한 한계점이 발생한다. 기존 머신러닝에 인공신경망(Artificial Neural Network)을 추가해 데이터로부터 컴퓨터 스스로 표현을 학습하는 방식이 바로 딥러닝이다. 여러 층을 겹겹이 쌓아 올려 구성한 신경망을 모델로 사용하여 학습에 상용되며, 딥러닝의 딥(Deep)이란 단어는 바로 이러한 연속된 층을 깊게 쌓아둔다는 점에서 나온 것이다. 인공신경망을 사용하면 단순한 선형 관계로 모델링하는 것이 아닌 복잡한 비선형 관계로 모델링 할 수 있게 된다.
딥러닝의 동작과정
인공신경망은 입력층(Input Layer), 은닉층(Hidden Layer) 그리고 출력층(Output Layer)이 중첩한 구조를 말한다. 입력층을 통해서 데이터를 입력받고 은닉층을 지나면서 처리되어 출력층을 통해 최종 결과가 출력된다. 모든 층은 가중치를 담고 있으며 각 층에서 일어나는 연산은 각 층의 가중치를 파라미터로 가지는 함수로 표현된다.
이러한 딥러닝의 동작과정은 다음과 같다. 먼저 초기에 신경망의 가중치를 랜덤 한 값으로 설정하고 신경망을 통과하여 데이터에 대한 예측 값을 확인한다. 손실 함수(Loss Function)를 통해 신경망의 예측과 실제 값이 얼마나 차이가 나는지 측정한다. 그 결과를 바탕으로 손실이 감소되는 방향으로 가중치를 수정한다. 그 수정하는 과정이 바로 딥러닝의 핵심인 역전파(Backpropagation)이다. 이 과정을 충분히 반복하여 결과를 잘 예측하는 최적의 가중치를 찾는 것이 딥러닝의 목표이다.
딥러닝의 발전과정
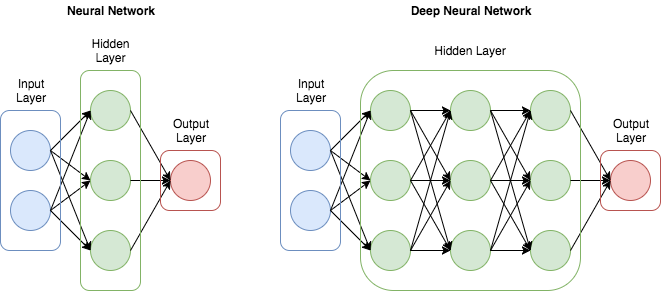
초기의 딥러닝은 은닉층이 많을수록 성능이 향상되는 것에 착안하여 은닉층을 많이 늘린 DNN(Deep Neural Network)이라는 기법을 사용했다. 그러면 최대한 깊게 만들수록 좋을까? 아니다. 망이 깊어질수록 과적합(Overfitting)이 되거나 연산량이 과도하게 늘어날 수 있다. 또한, 가중치는 역전파 과정을 통해서 갱신되는데 그 기울기(Gradient)가 연산이 거듭되면서 점차적으로 작아지거나(Gradient Vanishing) 비정상적으로 커지는(Gradient Exploding) 문제가 발생할 수 있다. 이러한 문제를 해결하고 개선하면서 CNN, RNN 등 다양한 알고리즘이 등장하게 된다. (딥러닝을 발전하게 한 다양한 기법들은 추후 천천히 다뤄보기로 하자.)
오늘날의 딥러닝은 비약적으로 성장했고, 다양한 부분에서 놀라운 성과를 보여주고 있다. 카메라만으로 구현한 Tesla의 자율주행 AI, 구글이나 네이버 등 다양한 기업에서 상용화하고 있는 음성인식 기술 그리고 전문의도 지나친 암을 진단하는 Lunit의 유방암 및 폐암 진단 AI 등 다양한 산업에서 폭넓게 사용되고 있다.
끝으로 딥러닝은 앞으로의 가능성이 무궁무진하다고 생각한다. 정말 다양한 산업분야에서 이미 적용되고 있고, 앞으로도 더 적용될 것이다. 언젠가는 그런 AI를 앞장서서 개발할 수 있는 개발자가 되고 싶다.
'Study > AI' 카테고리의 다른 글
| 모델의 평가지표란? (0) | 2022.02.06 |
|---|---|
| 데이터가 충분하다고 말하려면 얼마나 있어야 할까? (0) | 2022.01.24 |
| Deep Learning Library for video understanding (0) | 2021.11.30 |
| Knowledge Distillation 구현 (0) | 2021.11.29 |
| [Pytorch] Tips for Loading Pre-trained Model (0) | 2021.11.27 |