
머신러닝 모델을 학습할 때, 모델의 성능을 평가하는 방법은 무엇이 있을까?
데이터 준비와 모델 학습과 더불어 모델 성능을 측정하는 것 또한 머신러닝의 핵심 단계라고 할 수 있다.
그렇다면, 머신러닝 모델의 평가지표(Evaluation Metric)에는 무엇이 있는지 한번 살펴보자.
평가지표란?
모델의 학습은 어떻게 평가할 수 있을까? 정확도만 가지고 측정이 가능할까? 정확도로만 학습을 진행한다면, 모델은 실제 사용 환경에서 처음 만나는 데이터에 대해 약한 모습을 보일 가능성이 크다. 학습의 목적에 따라서 그에 맞는 적절한 평가지표를 사용해야 올바른 성능평가를 진행할 수 있다. 앞으로 올바른 성능평가를 할 수 있도록 대표적인 평가지표들은 무엇이 있는지 살표보고 비교해보자.
모델 정확도 (Model Accurancy)
모델 정확도란?
모델 정확도란 전체 표본 중 정확히 분류된 표본의 수를 의미한다. 여기서 정확히 분류된 표본이란 무엇을 의미할까? 우선 아래의 Confusion Matric를 살펴보자.

TP, FN, FP, TN의 네 가지로 분류됨을 알 수 있다. 여기서 각각의 의미를 살펴보자면, True와 False는 예측한 것이 정답과 일치하는지를 의미하며 Positive와 Negative는 예측의 여부를 말한다. 다음 예시로 각각의 의미를 한번 알아보자.

[강아지 사진을 보여주는 경우]
True Positive
강아지가 맞다고 예측하는 경우(True), 모델이 정답(Positive)을 맞춤
False Negative
강아지가 아니라고 예측하는 경우(False), 모델이 정답을 오답(Negative)이라고 생각함

[강아지 사진이 아닌 경우]
False Positive
강아지가 맞다고 예측하는 경우(True), 모델이 오답을 정답(Positive)이라고 생각함
True Negative
강아지가 아니라고 예측하는 경우(False), 모델이 오답(Negative)을 맞춤
그렇다면, 여기서 TP와 TN의 경우가 정확히 분류된 표본이라고 볼 수 있다.
Accurancy = 정확히 분류된 표본 (TP+TN) / 전체 표본 (TP+FN+FP+TN)
정확도만 높으면 좋을까?
하지만 정확도의 방법에는 문제점이 있는데, 단지 예측의 성공에만 초점을 둔다는 것이다. 전체 표본의 편중(Bias)을 고려해야 할 필요가 있는데, 만약 전체 표본에서 강아지의 비율이 99.99%라면 다 강아지라고 예측해도 모델은 99% 이상의 정확도를 보여줄 것이다. 이 경우에는 강아지가 아닌 다른 것들을 제대로 분류하는지 알 수 없다.
만약에 암 환자를 구분하는 경우라고 생각하면 그 문제는 더 심각하다. 대부분의 경우 정상이므로, 정상이라고 예측하면 높은 정확도를 보여줄 것이다. 이 경우 높은 정확도의 모델이지만 암 환자를 제대로 예측하지 못하는 심각한 문제가 발생할 수 있다.
정밀도와 재현율 (Precision and Recall)
앞선 정확도의 경우 전체 표본이 불균형한 경우 제대로 파악할 수 없다는 문제점이 있었다. 이러한 문제에서 고려해 볼 수 있는 평가지표가 바로 정밀도와 재현율이다.
재현율(Recall)이란?
재현율은 실제 정답 중에서 모델이 정답이라고 맞춘 수를 의미한다.
Recall = 정답을 맞춘 수 (TP) / 실제 정답 전체 (TP+FN)
재현율이 높다는 것은 모델이 관련있는 결과를 최대한 많이 가져온다는 것을 의미한다.
정밀도(Preicision)이란?
정밀도는 모델이 정답이라고 에측한 것 중에서 실제로 정답인 수를 의미한다.
Precision = 실제로도 정답인 수 (TP) / 정답이라고 예측한 수 (TP+FP)
정밀도가 높다는 것은 모델이 관련있는 결과를 그렇지 않은 것 대비 많이 맞추었다는 것을 의미한다.
그렇다면 모델의 효율성은 어떻게 따질까?
재현율이 높기만 하다고 좋은 모델이라고 할 수 없다. 모든 예측 결과를 정답이라고 한다면, 정확도는 낮아도 정답은 정답이라고 예측하니 재현율은 100%가 나올 것이다. 마찬가지로, 정밀도도 높기만 하다고 좋은 모델이라고 할 수 없다. 모델의 효율성을 따지기 위해 두 가지를 모두 검토할 필요가 있다.
Precision과 Recall의 Trade-Off
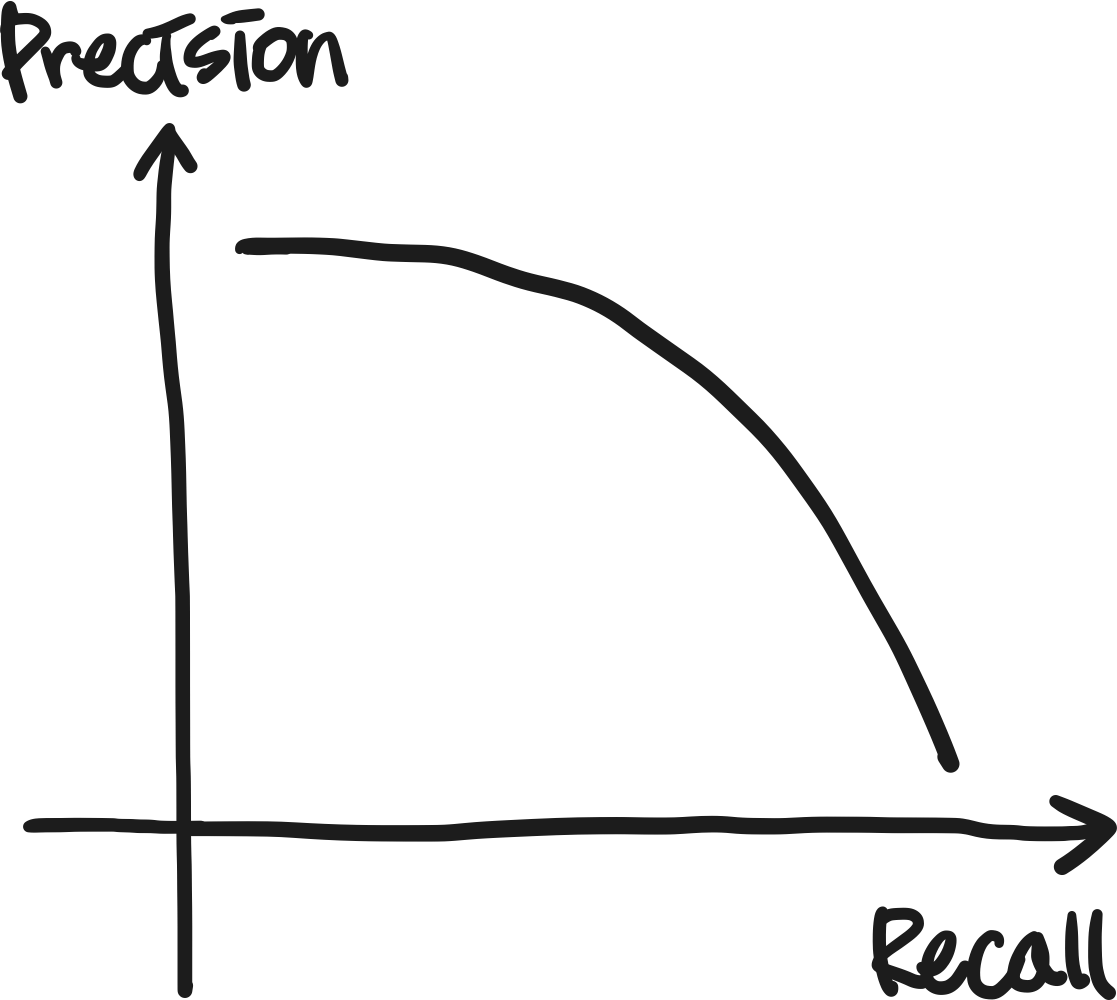
재현율과 정밀도를 모두 고려하다 보면, 서로 반대된다는 점을 확인할 수 있다. 좋은 모델을 위해서는 이러한 Trade-Off에서 최적의 지점을 찾을 필요가 있는데, 목적에 따라서 둘 중 하나에 더 치중하거나 F1 Score라는 평가지표를 사용하게 된다.
사고를 예측하는 경우 크고 작은 사고를 최대한 많이 예측하는 경우 좋은 효과를 볼 수 있다. 이 경우에는 Precision이 어느 정도 낮더라고 Recall이 높다면 모델이 유용할 것이다.
반대로, 주식 매매 타이밍을 예측하는 경우 여러가지의 주식을 다루는 것보다는 정말 중요한 것들을 잘 관리할 수만 있다면 괜찮다. 이런 경우에는 Recall 보다는 Precision에 치중하게 될 것이다.
이외에, 암 환자를 예측하는 경우 시간, 비용적인 부분과 사람의 생명 모두 고려하기 위해서는 두 가지 모두가 정말 중요한 경우도 있다. 이렇듯 목적에 따라서 적절한 Recall과 Precision를 찾는 것이 중요하다.
F1 Score란?
F1 Score는 Precision과 Recall의 조화평균을 의미한다. 여기서 일반적인 평균이 아닌 조화 평균을 계산한 이유는 Precision과 Recall이 0에 가까울수록 F1 Score도 동일하게 낮은 값을 갖도록 하기 위함이다.
F1 Score = (2 * Precision * Recall) / (Precision + Recall)
F1 Score는 Precision과 Recall을 모두 고려하는 평가지표로, 두 가지가 모두 중요한 경우 사용될 수 있다.
더 알아보기
다음으로는 Object Detection, Segmentation에서 자주 사용하는 Metric에 대해서 살펴보자.
IoU (Intersection over Union)
예측이 객체에 대해 정확히 그려졌는지를 결정하기 위해 IoU 또는 Jaccard Index를 사용한다. IoU란 예측한 Bounding Box와 실제 객체의 Bounding Box의 겹치는 구간을 두 구간의 합으로 나눈 것을 의미한다. 일반적으로 IoU를 임계값 기준으로 이상인 경우 TP로 이하인 경우는 FP로 간주한다.
IoU = Area of Overlap / Area of Union
AP (Average Precision)
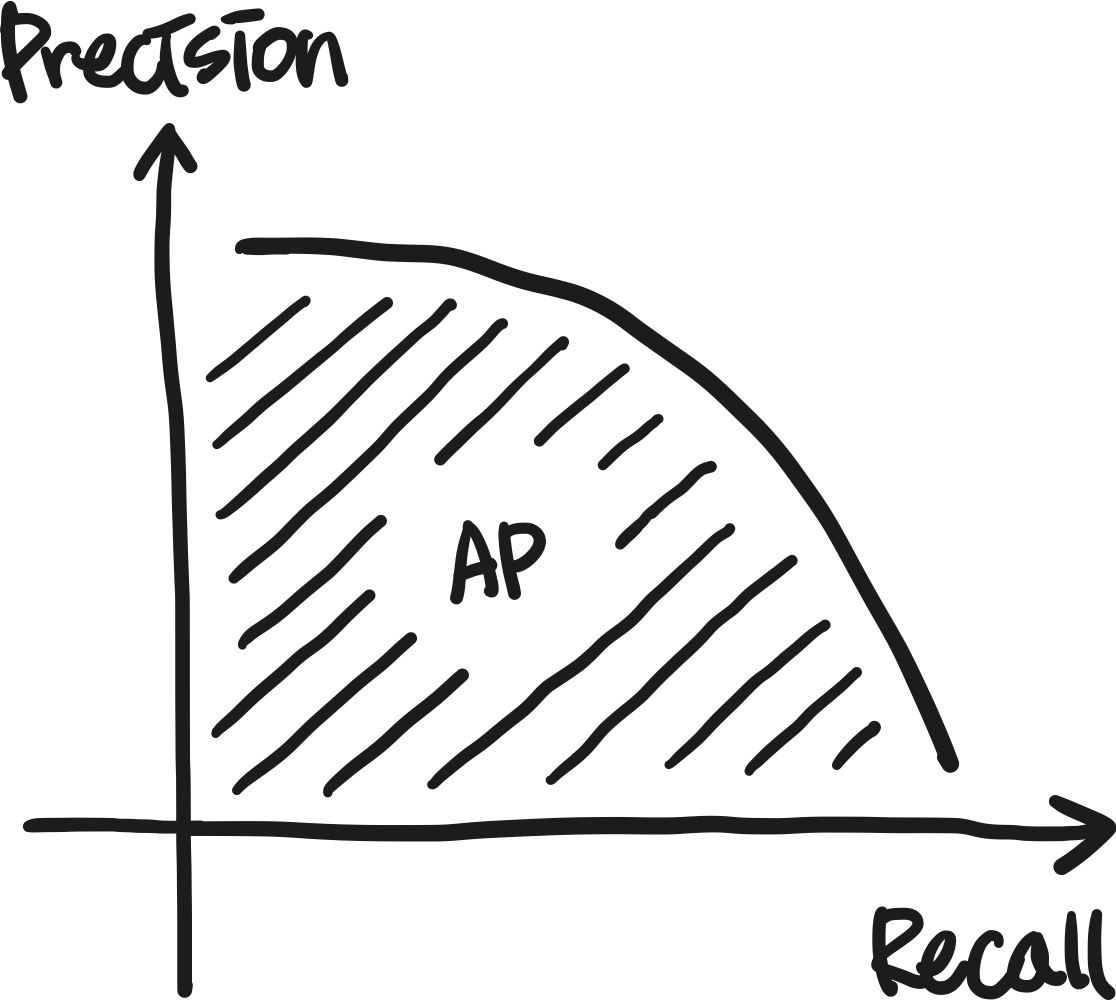
우선으로 AP라는 개념에 대해서 알아보자. PR Curve는 Recall의 변화에 따른 Precision을 나타낸 그래프를 의미한다. 즉, x축이 Recall, y축이 Precision이다. 이때 곡선의 면적이 바로 AP를 의미한다.
mAP (Mean Average Precision)
앞서 알아본 AP가 클래스 하나의 값이라면, mAP는 여러 클래스에 대한 AP값들의 평균을 의미한다. IoU를 사용해서 TP와 FP을 나누고 이를 바탕으로 AP를 구해 평균을 구한다.
Pascal VOC와 MS COCO는 mAP를 약간 다른 방법을 통해서 구한다. Pascal VOC의 경우 PR Curve의 AUC(Area Under Curve)를 사용한다. 즉, Recall의 모든 포인트를 사용한다. MS COCO의 경우 서로 다른 IoU 임계값마다 101개의 Recall Point를 사용한다.
끝으로
IoU을 사용하는 경우와 mAP를 사용하는 경우 모델의 학습 결과는 어떻게 달라질까?
'Study > AI' 카테고리의 다른 글
| Inductive Bias란 무엇일까? (10) | 2022.02.21 |
|---|---|
| 딥러닝의 핵심, 역전파 (0) | 2022.02.13 |
| 데이터가 충분하다고 말하려면 얼마나 있어야 할까? (0) | 2022.01.24 |
| 딥러닝이란 무엇일까? (0) | 2022.01.15 |
| Deep Learning Library for video understanding (0) | 2021.11.30 |