
Quantization 알아보기
Quantization이란?
Quantization, 한국말로 양자화. Quantization의 사전적 의미는 분야마다 다르게 해석될 수 있는데, 물리에서는 '어떤 연속적인 양을 이산적인 양으로 만드는 것', 수학이나 신호 처리에서는 '아날로그 신호를 특정 대표값으로 나타내어 디지털 신호로 변환하는 것'이라고 정의한다. 넓은 의미로 '어떤 측정된 양을 기본 단위로 치환하는 것'라고 볼 수 있다.
딥러닝에서 Quantization이란?
그렇다면 딥러닝에서 Quantization은 어떤 의미로 해석될까? 딥러닝에서 Quantization은 일반적으로 사용하는 floating point precision보다 낮은 bitwidths로 tensor를 저장하는 기술을 의미한다. 예컨데, 일반적으로 FP32 모델을 INT8 모델로 치환하여, 결과적으로 연산량을 줄이고 연산 속도를 높이기 위해 사용한다.
딥러닝에서는 Quantization뿐 아니라 Pruning 그리고 Knowledge Distillation 등 다양한 경량화 기법이 있다. 각각의 방법에는 장단점이 있으며, 이 글에서는 그 중에서 Quantization에 대해 다루고자 한다.
Quantization의 종류
Quantization의 종류는 어떤 것이 있을까?
하드웨어나 프레임워크마다 지원하는 종류가 다르지만, 대표적인 구분 방법은 다음과 같다.
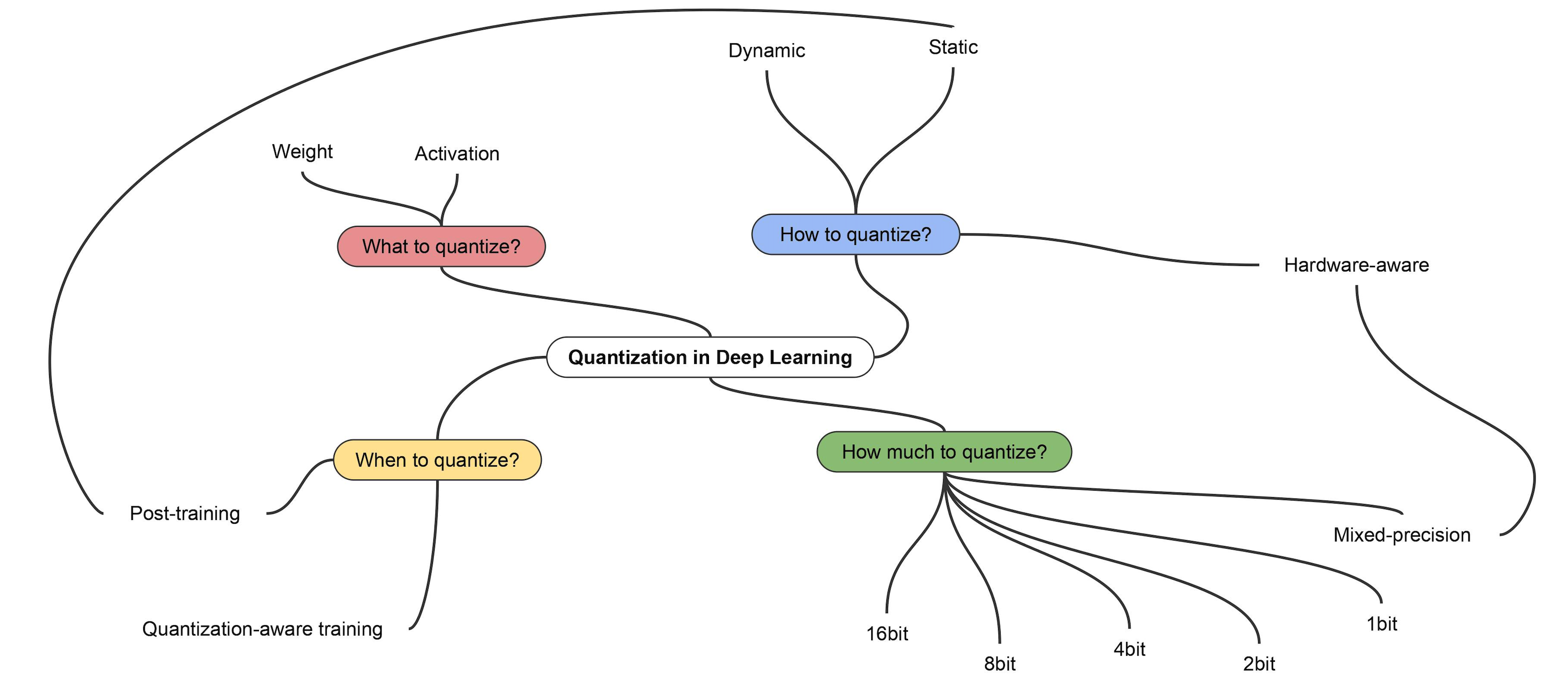
PTQ(Post-Training Quantization)와 QAT(Quantization-Aware Training)
PTQ는 이미 학습이 끝난 모델을 Quantization 통해 경량화하는 방법이다. 일반적으로 모델의 출력값 범위가 고르게 분포되어 있지 않기 때문에, 단순히 출력을 기존 32bit, 16bit에서 8bit로 조절한다면, 모델의 성능이 많이 떨어질 수 있다. 데이터를 통과시켜 나오는 출력값에 따라 scale을 조절하여, Quantization으로 인한 손실을 최소화하는 것이 관건이다. 최근에는 각 layer 별로 scale을 정하는 방법까지 사용하기도 한다.
QAT는 학습 단계에서 미리 Inference에 Quantization을 적용하여, 최적의 가중치를 구하는 방식이다. 앞선 PTQ의 방법과 비교해서, 모델을 추가로 학습해야 하는 단점이 있지만 학습 과정부터 적용하다 보니 성능 하락을 최소화할 수 있다. 파라미터 사이즈가 크고, 정확도가 중요한 모델이 아니라면 QAT의 사용은 필연적이라고 볼 수 있다.
Static Quantization와 Dynamic Quantization
Static과 Dynamic은 Quantization을 적용하기 위해 scale을 어떻게 조절하는지에 따라 달라진다. Static Quantization의 경우 샘플 데이터를 받아 미리 계산한 고정된 값을 사용하기 때문에 추가적인 연산 과정이 필요하지 않다. Dynamic Quantization의 경우에는 동작 중에 동적으로 계산해서 사용하는 방법으로 추가적인 연산이 필요하지만 비교적 Static Quantization의 방법보다 더 좋은 성능을 갖는다.
Quantization의 한계점
Quantization GPU 연산이 가능한 프레임워크?
TensorFlow, Torch와 같은 대표적인 프레임워크 대부분 Quantization 기능을 지원한다. 하지만 기초적인 레이어 외에는 제대로 지원하지 않는 경우도 많아 모델의 모든 레이어에 적용하지 못할 수 있고, 사용하는 프레임워크에 따라서 GPU 연산을 지원하지 않을 수 있다. 이러한 점들을 사전에 확인하고, 다른 경량화 기법들과 함께 사용하는 것을 권장한다.
생성모델에서의 Quantization?
사용하기 쉽지는 않지만, 그래도 속도를 비약적으로 올릴 수 있는 Quantization. 아쉽게도 생성모델에서는 다른 도메인에 비해서, Quantization은 정말 사용하기 어려운 기술이라고 생각된다. 생성 결과물이 의도와 다르게 나오거나 노이즈가 낀 듯한 이미지가 생성되는 듯한 결과물을 얻게 된다.

생성모델에서의 Quantization을 연구한 논문을 살펴보면, 전반적으로 PTQ보다는 QAT를 적용한 경우 더 좋은 결과물을 확인할 수 있다. 모델의 사용 용도에 따라서 결과물에 어느 정도 타협을 두고 QAT를 적용한다면, 사용 가능할 것이다.
다른 도메인에서는 Quantization이 자주 사용되는 기술 중 하나인데, 유독 생성모델에서는 사용되지 않는 경향이 있는 것 같다. 그 이유는 무엇일까? 예를 들면, Classification 모델이라면 Quantization 적용 이후 정확도가 다소 떨어질 수 있다. 정확도가 조금 떨어진다고 해도 필요한 작업을 수행하는 것에는 부족함이 없을 것이다. 하지만, 생성모델의 경우 정확도라는 개념이 없다. 가끔 잘못 판별하거나 신뢰도가 낮아지는 것이 아니라 결과물 자체의 퀄리티가 떨어지게 된다. 혹은 Quantization을 적용할 만큼 속도가 중요하지 않은 Task일 수 있다. 다양한 이유가 있겠지만, 최근 ChatGPT, Stable Diffusion 등 생성모델이 자주 사용되고 있는 만큼 새로운 최적화 기법이 나오지 않을까 싶다.
References
- Pavel Andreev, "QUANTIZATION OF GENERATIVE ADVERSARIAL NETWORKS FOR EFFICIENT INFERENCE"
- https://developer.nvidia.com/ko-kr/blog/achieving-fp32-accuracy-for-int8-inference-using-quantization-aware-training-with-tensorrt/
- https://gaussian37.github.io/dl-concept-quantization/
- https://blogik.netlify.app/BoostCamp/U_stage/46_quantization/
- https://pytorch.org/docs/stable/quantization.html
의견과 질문은 언제나 감사합니다.
'Study > AI' 카테고리의 다른 글
| Inductive Bias란 무엇일까? (10) | 2022.02.21 |
|---|---|
| 딥러닝의 핵심, 역전파 (0) | 2022.02.13 |
| 모델의 평가지표란? (0) | 2022.02.06 |
| 데이터가 충분하다고 말하려면 얼마나 있어야 할까? (0) | 2022.01.24 |
| 딥러닝이란 무엇일까? (0) | 2022.01.15 |